
[Editor's note: This story was updated June 3, 2020. The changes are clearly marked below.]
Back in December, when AWS launched its new machine learning IDE, SageMaker Studio, we wrote up a “hot-off-the-presses” review. At the time, we felt the platform fell short, but we promised to publish an update after working with AWS to get more familiar with the new capabilities. This is that update.
Pain points and solutions in the machine learning pipeline
When Amazon launched SageMaker Studio, they made clear the pain points they were aiming to solve: “The machine learning development workflow is still very iterative, and is challenging for developers to manage due to the relative immaturity of ML tooling.” The machine learning workflow — from data ingestion, feature engineering, and model selection to debugging, deployment, monitoring, and maintenance, along with all the steps in between — can be like trying to tame a wild animal.
To solve this challenge, big tech companies have built their own machine learning and big data platforms for their data scientists to use: Uber has Michelangelo, Facebook (and likely Instagram and WhatsApp) has FBLearner flow, Google has TFX, and Netflix has both Metaflow and Polynote (the latter has been open sourced). For smaller organizations that cannot roll out their own infrastructure, a number of players have emerged in proprietary and productized form, as evidenced by Gartner’s Magic Quadrant for Data Science and Machine Learning Platforms:
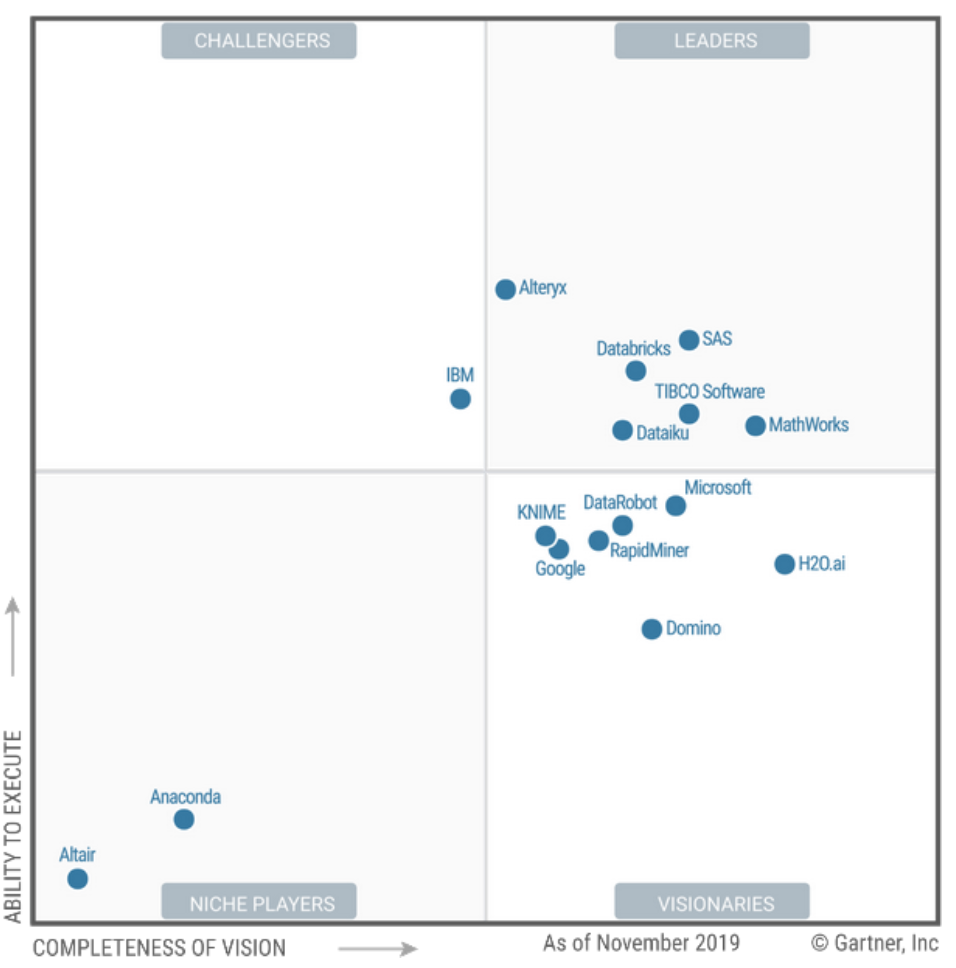
These include platforms like Microsoft Azure, H20, DataRobot, and Google Cloud Platform (to name a few). These platforms are intended for data scientists and adjacent roles, such as data engineers and ML engineers, and span all types of data work, from data cleaning, wrangling, and visualization, to machine learning. Amazon SageMaker Studio was the latest to join this fray.
What SageMaker Studio Offers
So what does Sagemaker Studio offer? According to Amazon, “SageMaker [including Studio] is a fully managed service that removes the heavy lifting from each step of the machine learning process.” The tools are impressive and do remove several aspects of the heavy lifting:
- The IDE meets data scientists where they are by using the intuitive interface of JupyterLab, a common open notebook-based IDE for data science in Python. Standardizing on what are rapidly becoming (or have already become) the standard tools for data professionals allows everyone to leverage the wide range of open-source tooling available in the ecosystem. This seems to be an area where AWS is making a solid commitment, having hired two major JupyterLab contributors, including Brian Granger, co-lead of Project Jupyter itself.
- Sagemaker notebooks can be run elastically, which means data scientists pay only for compute time used, instead of for how long they have the notebook open. This makes for a far more cost efficient workflow for data scientists. Elastic notebooks also allow heavy-duty machine learning workloads to complete quickly by rapidly scaling up and down compute infrastructure to meet demand, all with minimal configuration.
- SageMaker Studio provides a framework to track and compare model performance on validation sets across different models, architectures, and hyperparameters (this beats doing it in spreadsheets!). The formalization of machine learning model building as a set of experiments is worth focusing on: You can find countless posts on how much trouble data scientists have tracking machine learning experiments. It is exciting to be able to view ML experiments on a leaderboard, ranked by a metric of choice, although we need to be careful since optimizing for single metrics often results in algorithmic bias.
- The debugger provides real-time, graphical monitoring of common issues that data scientists encounter while training models (exploding and vanishing gradients, loss function not decreasing), as well as the ability to build your own rules. This removes both a practical and a cognitive burden, freeing data scientists from the need to constantly monitor these common issues as SageMaker Studio will send alerts.
- The platform also includes an automatic model building system, Autopilot. All you need to do is provide the training data, and SageMaker performs all the feature engineering, algorithm selection, and hyperparameter tuning automatically (similar to DataRobot). An exciting feature is the automatic generation of notebooks containing all the resulting models that you can play with and build upon. Amazon claims the automated models can serve either as baselines (for scientists wanting to build more sophisticated models) or as models to be productionized directly. The latter may be problematic, particularly as users are not able to select the optimization metric (they can only provide the training data). We all know about the horrors of proxies for optimization metrics and the potential for “rampant racism in decision-making software.” When we asked AWS about this, a spokesperson told us: “As with all machine learning, customers should always closely examine training data and evaluate models to ensure they are performing as intended, especially in critical use cases such as healthcare or financial services." (Update: There is now a limited selection of optimization metrics that can be selected via code after automatically generating notebooks. However, the GUI still does not allow the selection of metrics. Given that Autopilot is marketed to non-coder GUI-based users, we would encourage AWS to add optimization metric selection to the GUI as well. We would also like to see the inclusion of other metrics like Precision and Recall, not just F1.)
- The model hosting and deployment allows data scientists to get their models up and running in production directly from SageMaker notebook, and provides an HTTPS endpoint that you can ping with new data to get predictions. The ability to monitor data drift in new data over time (that is, to interrogate how representative of new data the training data is) is important and has some promise, especially when it comes to spotting potential bias. The built-in features are limited to basic summary statistics but there are ways for data scientists to build their own custom metrics by providing either custom pre-processing or post-processing scripts and using a pre-built analysis container or by bringing their own custom container.
Does SageMaker Studio deliver on its promise?
In contrast to data science platforms such as DataRobot and H20.ai, SageMaker takes a more “training wheels off” approach. It’s biggest proponents have mostly been either data scientists who have serious software engineering chops, or teams that have DevOps, engineering, infrastructural, and data science talent. Another way to frame the question is: Does SageMaker Studio allow lone data scientists with less engineering background to productively enter the space of building ML models on Amazon? After spending days with Studio, we think the answer is no. As noted above, the tools are powerful but, as with so much of AWS, the chaos of the documentation (or lack thereof) and the woefully difficult UX/UI (to compare ML experiments, click through to experiments tab, highlight multiple experiments, control-shift something something without any clear indication in the UI itself) mean the overhead of using products that are still actively evolving is too high.
This is why AWS hosts so many workshops, with and without breakout sessions, chalk talks, webinars, and events such as re:Invent. All parts of SageMaker Studio require external help and constant hacking away. For example, there’s a notebook with an xgboost example that we were able to replicate, but after searching for documentation, we still couldn’t figure out how to get scikit-learn (a wildly popular ML learning package) up and running. When, in preparation for writing this piece, we emailed our contact at Amazon to ask for directions to relevant documentation, they explained that the product is still “in preview.” (Update: since our initial exploration of SageMaker, AWS has been busy adding features. They now have more documentation and sample notebooks for scikit-learn in Sagemaker.) The best products teach you how to use them without the need for additional seminars. Data scientists (and technical professionals in general) greatly prefer to get started with a good tutorial rather than wait for a seminar to come through town.
SageMaker Studio is a step in the right direction, but it has a ways to go to fulfill its promise. There’s a reason it isn’t in the Gartner Magic Quadrant for Data Science and Machine Learning Platforms. (Correction: The Gartner Magic Quadrant was published November of 2019 and Sagemaker Studio was only released December of 2019 and would not have been included. AWS is a leader in the Gartner Magic Quadrant for Cloud AI Developer Services.) Like AWS, it still requires serious developer chops and software engineering skills and it’s still a long way from making data scientists themselves production ready and meeting them where they are. The real (unmet) potential of SageMaker Studio and the new features of SageMaker lie in efficiency gains and cost reductions for both data scientists who are already comfortable with DevOps and teams that already have strong software engineering capabilities.
Hugo Bowne-Anderson is Head of Data Science Evangelism and VP of Marketing at Coiled. Previously, he was a data scientist at DataCamp, and has taught data science topics at Yale University and Cold Spring Harbor Laboratory, conferences such as SciPy, PyCon, and ODSC, and with organizations such as Data Carpentry.
Tianhui Michael Li is president at Pragmatic Institute and the founder and president of The Data Incubator, a data science training and placement firm. Previously, he headed monetization data science at Foursquare and has worked at Google, Andreessen Horowitz, J.P. Morgan, and D.E. Shaw.