
Let the OSS Enterprise newsletter guide your open source journey! Sign up here.
Microsoft this week announced Tutel, a library to support the development of mixture of experts (MoE) models -- a particular type of large-scale AI model. Tutel, which is open source and has been integrated into fairseq, one of Facebook's toolkits in PyTorch, is designed to enable developers across AI disciplines to "execute MoE more easily and efficiently," a statement from Microsoft explained.
MoE are made up of small clusters of "neurons" that are only active under special, specific circumstances. Lower "layers" of the MoE model extract features and experts are called upon to evaluate those features. For example, MoEs can be used to create a translation system, with each expert cluster learning to handle a separate part of speech or special grammatical rule.
Compared with other model architectures, MoEs have distinct advantages. They can respond to circumstances with specialization, allowing the model to display a greater range of behaviors. The experts can receive a mix of data, and when the model is in operation, only a few experts are active -- even a huge model needs only a small amount of processing power.
In fact, MoE is one of the few approaches demonstrated to scale to more than a trillion parameters, paving the way for models capable of powering computer vision, speech recognition, natural language processing, and machine translation systems, among others. In machine learning, parameters are the part of the model that’s learned from historical training data. Generally speaking, especially in the language domain, the correlation between the number of parameters and sophistication has held up well.
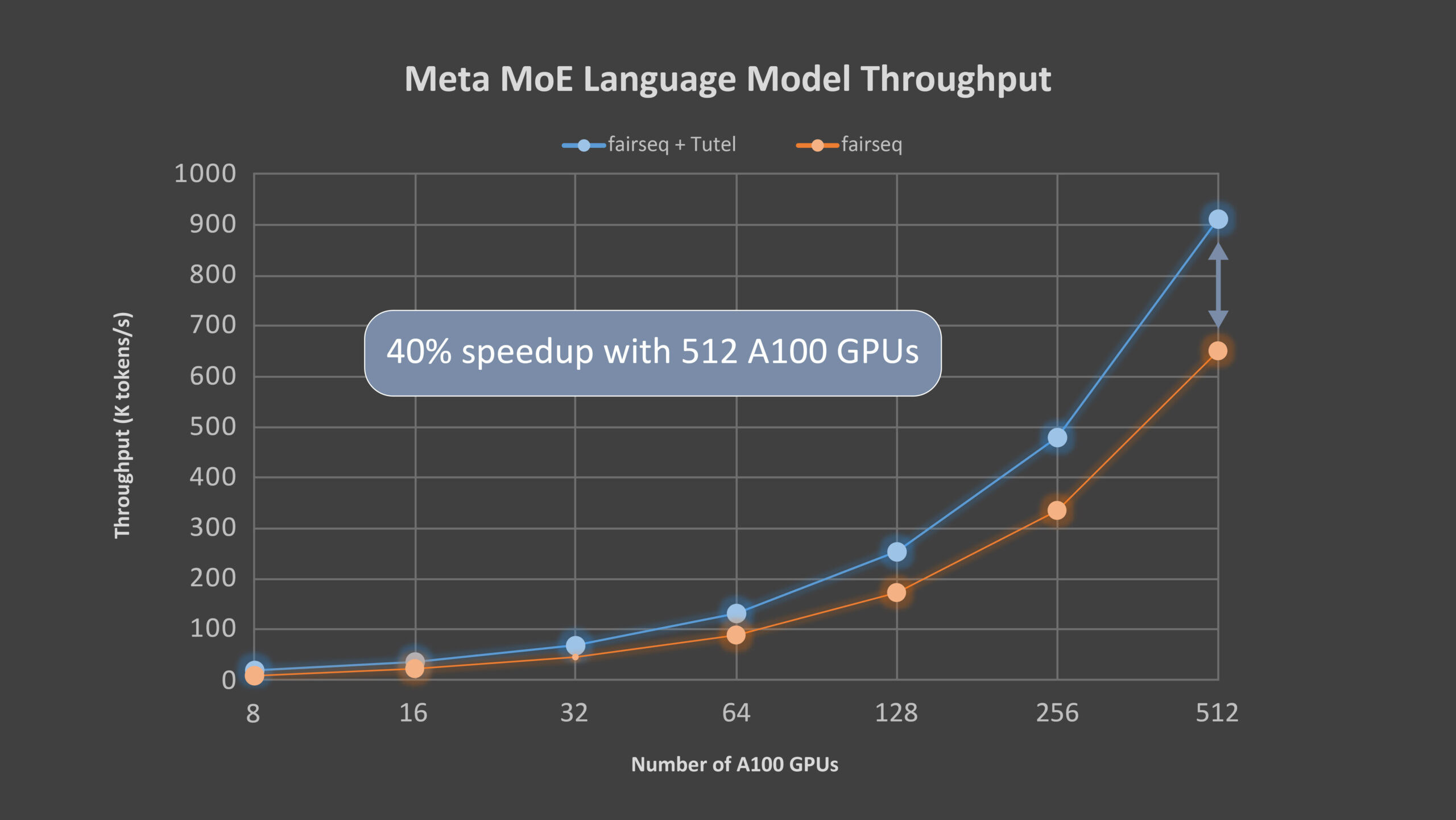
Tutel mainly focuses on the optimizations of MoE-specific computation. In particular, the library is optimized for Microsoft's new Azure NDm A100 v4 series instances, which provide a sliding scale of Nvidia A100 GPUs. Tutel has a "concise" interface intended to make it easy to integrate into other MoE solutions, Microsoft says. Alternatively, developers can use the Tutel interface to incorporate standalone MoE layers into their own DNN models from scratch.
"Because of the lack of efficient implementations, MoE-based models rely on a naive combination of multiple off-the-shelf operators provided by deep learning frameworks such as PyTorch and TensorFlow to compose the MoE computation. Such a practice incurs significant performance overheads thanks to redundant computation," Microsoft wrote in a blog post. (Operators provide a model with a known dataset that includes desired inputs and outputs). "Tutel designs and implements multiple highly optimized GPU kernels to provide operators for MoE-specific calculation."
Tutel is available in open source on GitHub. Microsoft says that the Tutel development team will "be actively integrating" various emerging MoE algorithms from the community into future releases.
"MoE is a promising technology. It enables holistic training based on techniques from many areas, such as systematic routing and network balancing with massive nodes, and can even benefit from GPU-based acceleration. We demonstrate an efficient MoE implementation, Tutel, that resulted in significant gain over the fairseq framework. Tutel has been integrated [with our] DeepSpeed framework, as well, and we believe that Tutel and related integrations will benefit Azure services, especially for those who want to scale their large models efficiently," Microsoft added.