
The path to achieving artificial general intelligence (AGI), AI systems with capabilities at least on par with humans in most tasks, remains a topic of debate among scientists. Opinions range from AGI being far away, to possibly emerging within a decade, to "sparks of AGI" already visible in current large language models (LLM). Some researchers even argue that today's LLMs are AGI.
In an effort to bring clarity to the discussion, a team of scientists at Google DeepMind, including Chief AGI Scientist Shane Legg, have proposed a new framework for classifying the capabilities and behavior of AGI systems and their precursors.
"We argue that it is critical for the AI research community to explicitly reflect on what we mean by 'AGI,' and aspire to quantify attributes like the performance, generality, and autonomy of AI systems," the authors write in their paper.
The principles of AGI
One of the key challenges of AGI is establishing a clear definition of what AGI entails. In their paper, the DeepMind researchers analyze nine different AGI definitions, including the Turing Test, the Coffee Test, consciousness measures, economic measures, and task-related capabilities. They highlight the shortcomings of each definition in capturing the essence of AGI.
For instance, current LLMs can pass the Turing Test, but generating convincing text alone is clearly insufficient for AGI, as the shortcomings of current language models show. Determining whether machines possess consciousness attributes remains an unclear and elusive goal. Moreover, while failing at certain tasks (e.g. making coffee in a random kitchen) may indicate that a system is not AGI, passing them does not necessarily confirm its AGI status.
To provide a more comprehensive framework for AGI, the researchers propose six criteria for measuring artificial intelligence:
Measures of AGI should focus on capabilities rather than qualities such as human-like understanding, consciousness, or sentience.
Measures of AGI should consider both generality and performance levels. This ensures that AGI systems are not only capable of performing a wide range of tasks but also excel in their execution.
AGI should require cognitive and meta-cognitive tasks, but embodiment and physical tasks should not be considered prerequisites for AGI.
The potential of a system to perform AGI-level tasks is sufficient, even if it is not deployable. "Requiring deployment as a condition of measuring AGI introduces non-technical hurdles such as legal and social considerations, as well as potential ethical and safety concerns," the researchers write.
AGI metrics should focus on real-world tasks that people value, which the researchers describe as "ecologically valid."
Lastly, the scientists emphasize that AGI is not a single endpoint but a path, with different levels of AGI along the way.
The depth and breadth of intelligence
DeepMind presents a matrix that measures "performance" and "generality" across five levels, ranging from no AI to superhuman AGI, a general AI system that outperforms all humans on all tasks. Performance refers to how an AI system's capabilities compare to humans, while generality denotes the breadth of the AI system's capabilities or the range of tasks for which it reaches the specified performance level in the matrix.
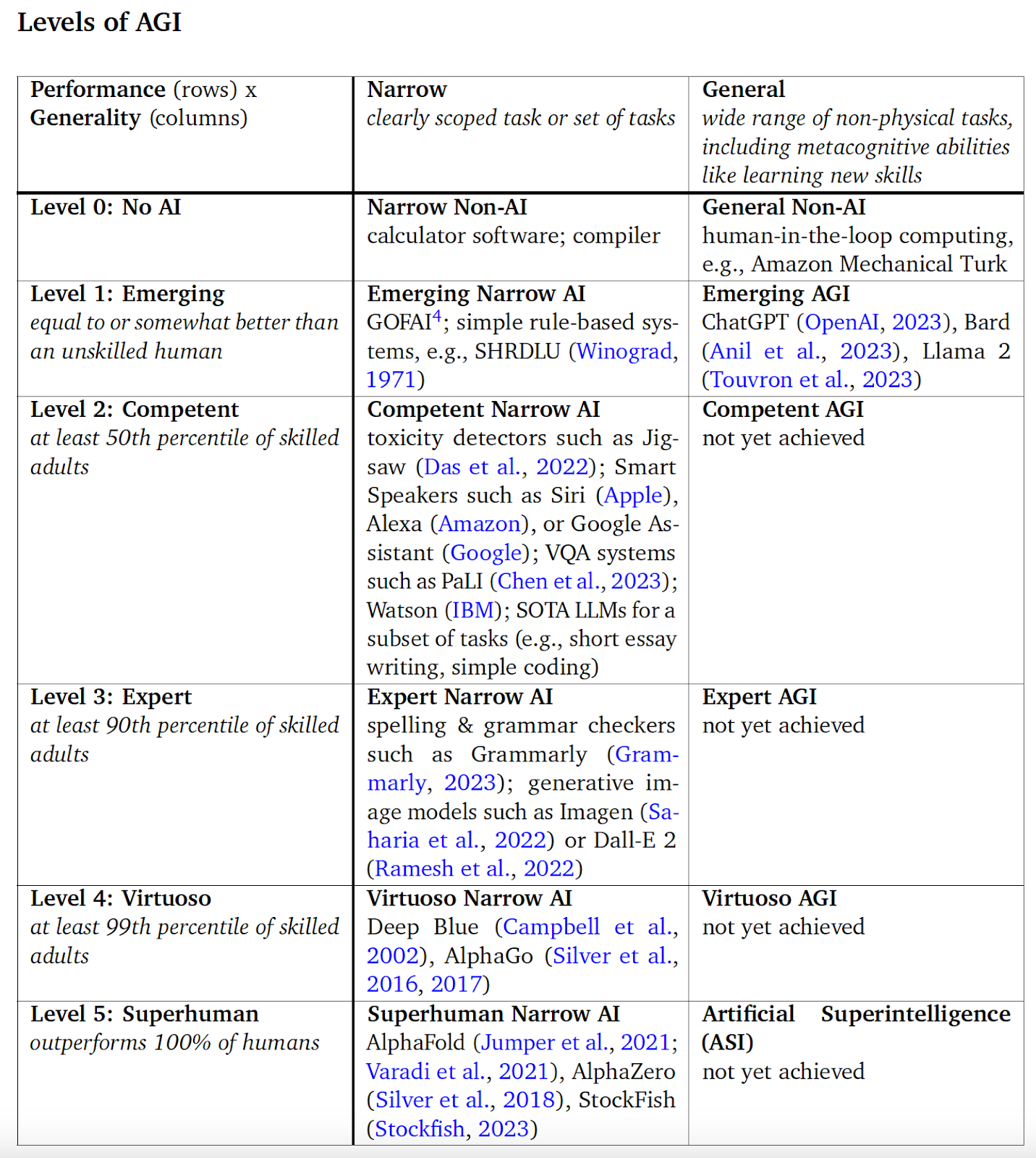
Image source: arxiv
The matrix also distinguishes between narrow and general AI. For instance, we already have superhuman narrow AI systems like AlphaZero and AlphaFold, which excel at very specific tasks. This matrix enables the classification of AI systems at different levels. Advanced language models such as ChatGPT, Bard, and Llama 2 are “competent” (Level 2) in some narrow tasks, like short essay writing and simple coding, and “emerging” (Level 1) in others, such as mathematical abilities and tasks requiring reasoning and planning.
"Overall, current frontier language models would therefore be considered a Level 1 General AI ('Emerging AGI') until the performance level increases for a broader set of tasks (at which point the Level 2 General AI, 'Competent AGI,' criteria would be met)," the researchers write.
The researchers also note that while the AGI matrix rates systems according to their performance, the systems may not match their level in practice when deployed. For example, text-to-image systems produce images of higher quality than most people can draw, but they generate erroneous artifacts that prevent them from achieving "virtuoso" level, which puts them in the 99th percentile of skilled individuals.
"While theoretically an 'Expert' level system, in practice the system may only be 'Competent,' because prompting interfaces are too complex for most end-users to elicit optimal performance," the researchers write.
DeepMind suggests that an AGI benchmark would encompass a broad suite of cognitive and metacognitive tasks, measuring diverse properties, including linguistic intelligence, mathematical and logical reasoning, spatial reasoning, interpersonal and intrapersonal social intelligence, the ability to learn new skills, and creativity.
However, they also acknowledge that it is impossible to enumerate all tasks achievable by a sufficiently general intelligence. "As such, an AGI benchmark should be a living benchmark. Such a benchmark should therefore include a framework for generating and agreeing upon new tasks," they write.
Autonomy and risk
DeepMind introduces a separate matrix for measuring autonomy and risk in AI systems. AI systems span from Level 0, where a human performs all tasks, to Level 5, representing fully autonomous AI, with various levels in between where humans and AI share tasks and authority.
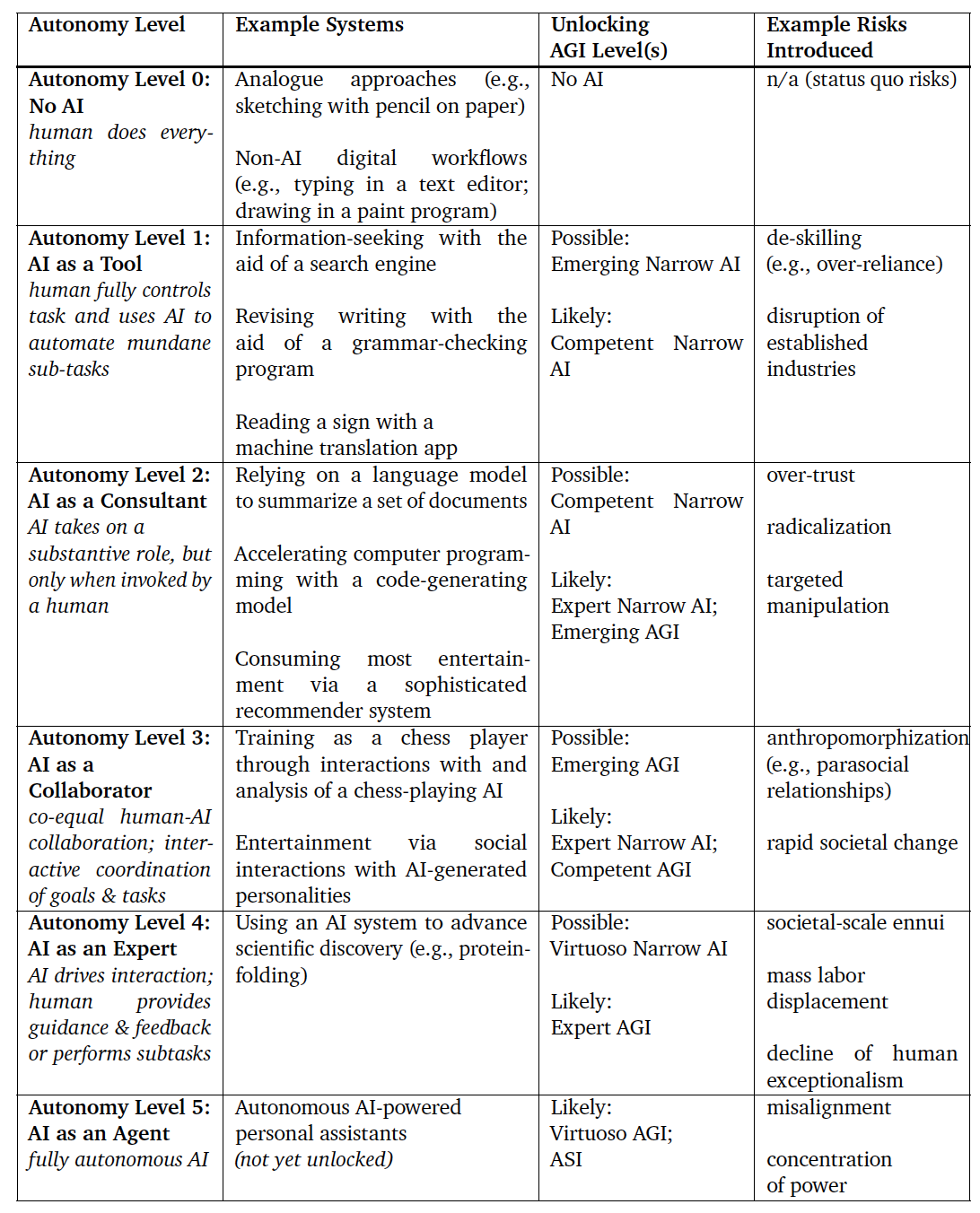
Image source: arxiv
Risks associated with AI systems vary depending on their level of autonomy. At lower levels, where AI acts as an augmenter of human skills, risks include deskilling and disruption of current industries. As autonomy increases, risks may involve targeted manipulation through personalized content, broader societal disruptions, and more serious damage caused by the misalignment of fully autonomous agents with human values.
DeepMind's framework, like all things concerning AGI, will have its own shortcomings and detractors. But it stands as a comprehensive guide for gauging where we stand on the journey toward developing AI systems capable of surpassing human abilities.