
In my previous blog post, I ranted a little about database technologies and threw a few thoughts out there on what I think a better data system would be able to do. In this post, I am going to talk a bit about the concept of the data lakehouse.
The term data lakehouse has been making the rounds in the data and analytics space for a couple of years. It describes an environment combining data structure and data management features of a data warehouse with the low-cost scalable storage of a data lake. Data lakes have advanced the separation of storage from compute, but do not solve problems of data management (what data is stored, where it is, etc). These challenges often turn a data lake into a data swamp. Said a different way, the data lakehouse maintains the cost and flexibility advantages of storing data in a lake while enabling schemas to be enforced for subsets of the data.
Let’s dive a bit deeper into the lakehouse concept. We are looking at the lakehouse as an evolution of the data lake. And here are the features it adds on top:
- Data mutation – Data lakes are often built on top of Hadoop or AWS and both HDFS and S3 are immutable. This means that data cannot be corrected. With this also comes the problem of schema evolution. There are two approaches here: copy on write and merge on read – we’ll probably explore this some more in the next blog post.
- Transactions (ACID) / Concurrent read and write – One of the main features of relational databases that help us with read/write concurrency and therefore data integrity.
- Time-travel – This can feature is sort of provided through the transaction capability. The lakehouse keeps track of versions and therefore allows for going back in time on a data record.
- Data quality / Schema enforcement – Data quality has multiple facets, but mainly is about schema enforcement at ingest. For example, ingested data cannot contain any additional columns that are not present in the target table’s schema and the data types of the columns have to match.
- Storage format independence is important when we want to support different file formats from parquet to kudu to CSV or JSON.
- Support batch and streaming (real-time) – There are many challenges with streaming data. For example the problem of out-of order data, which is solved by the data lakehouse through watermarking. Other challenges are inherent in some of the storage layers, like parquet, which only works in batches. You have to commit your batch before you can read it. That’s where Kudu could come in to help as well, but more about that in the next blog post.
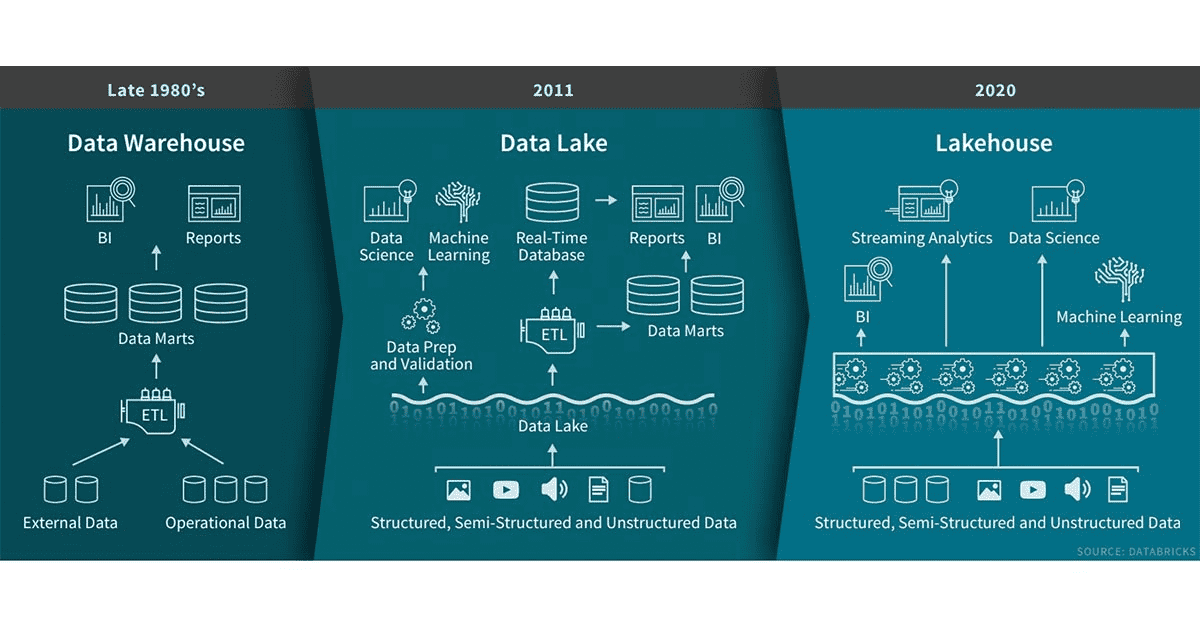
The evolution of the data lakehouse. Source:
The evolution of the data lakehouse. Source: DataBricks
If you are interested in a practitioners view of how increased data loads create challenges and how a large organization solved them, read about Uber’s journey that ended up in the development of Hudi, a data layer that supports most of the above features of a Lakehouse. We’ll talk more about Hudi in our next.